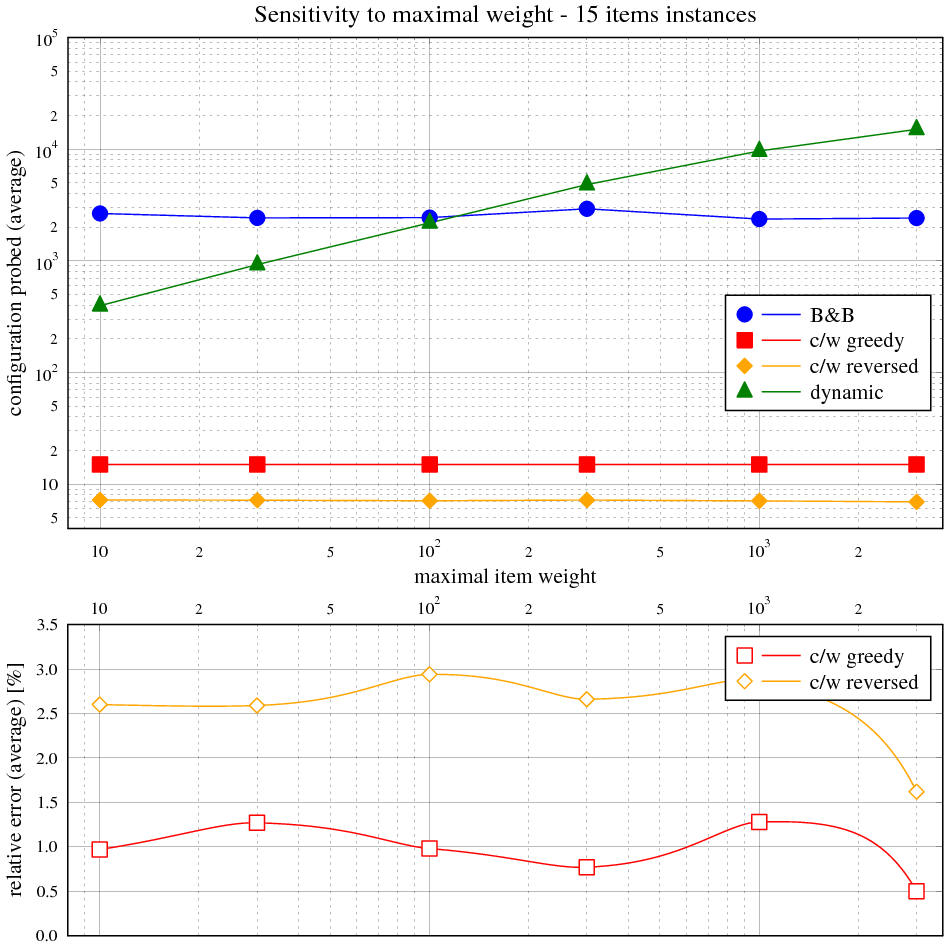
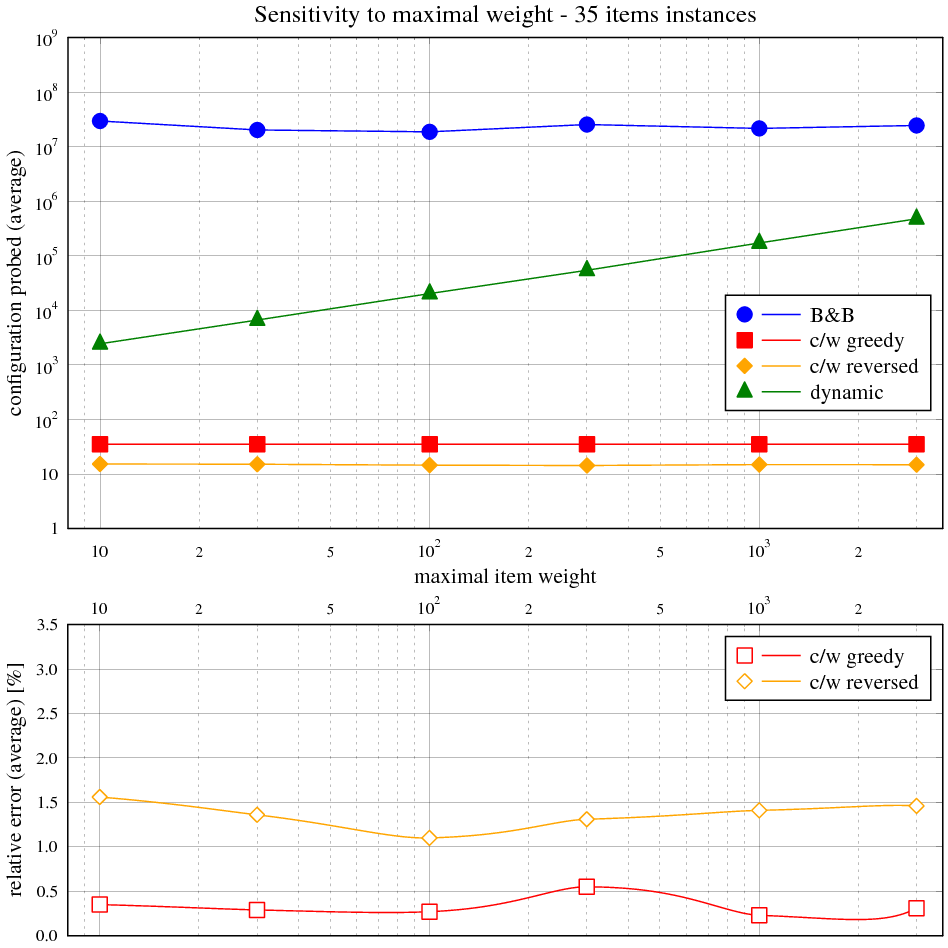
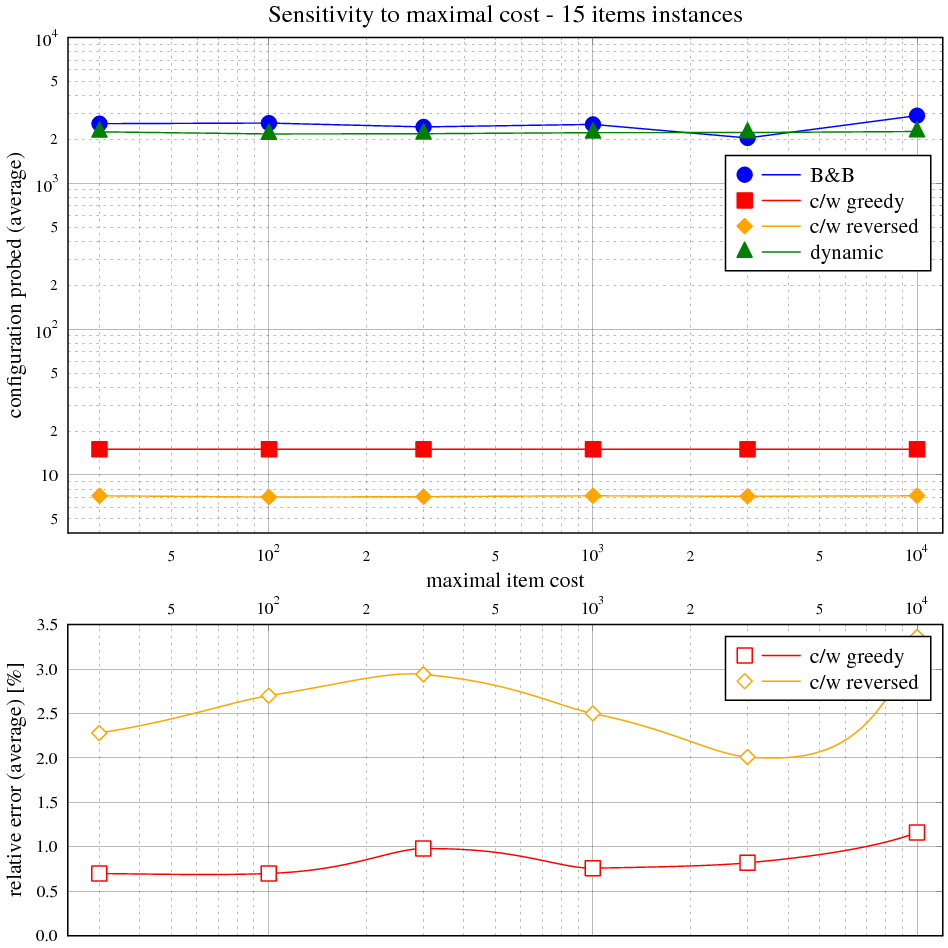
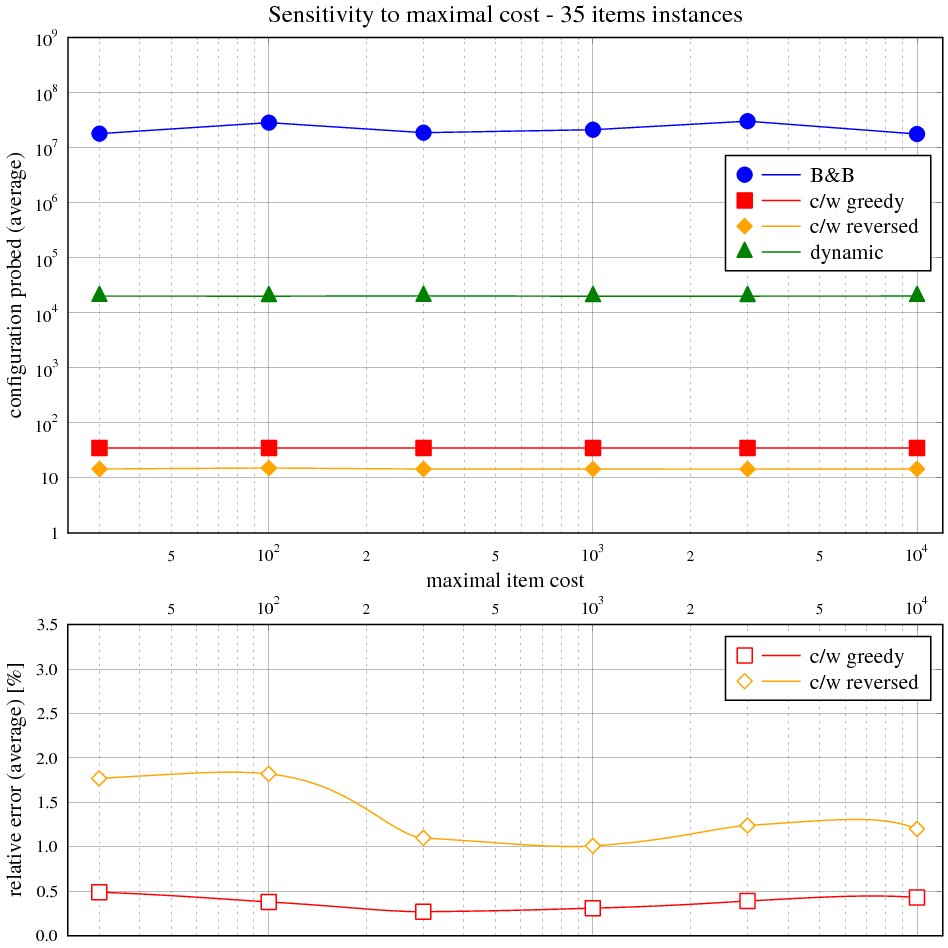
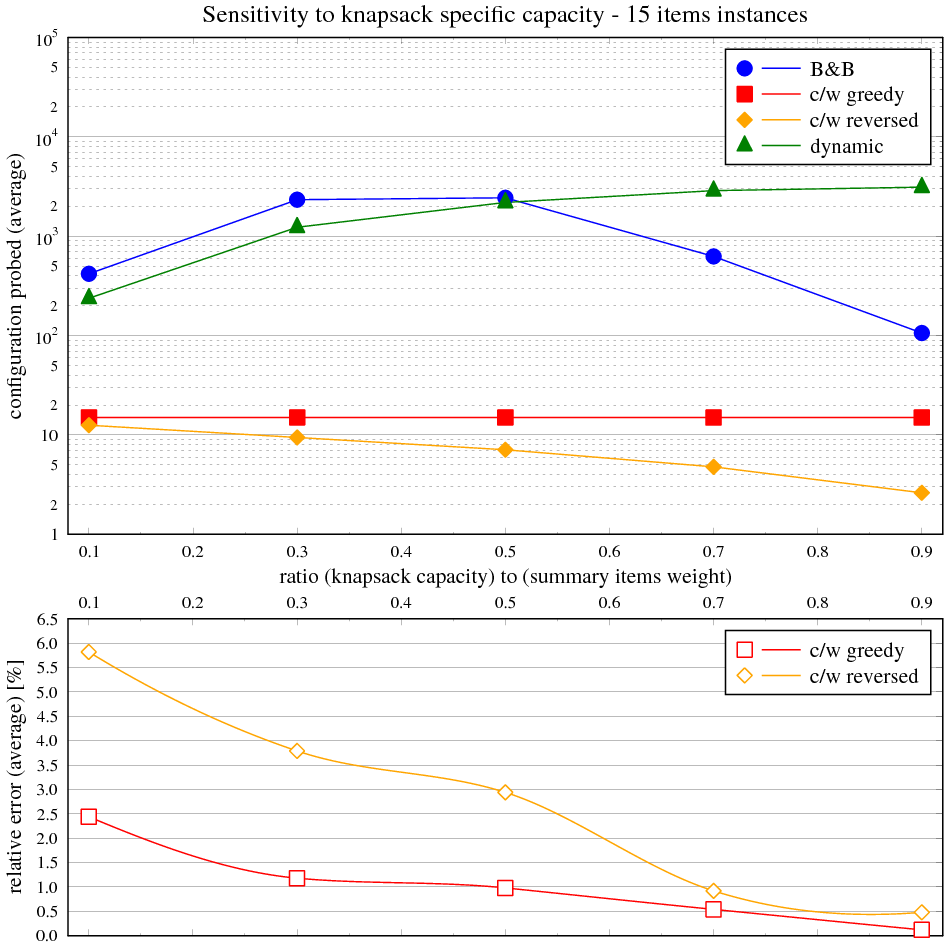
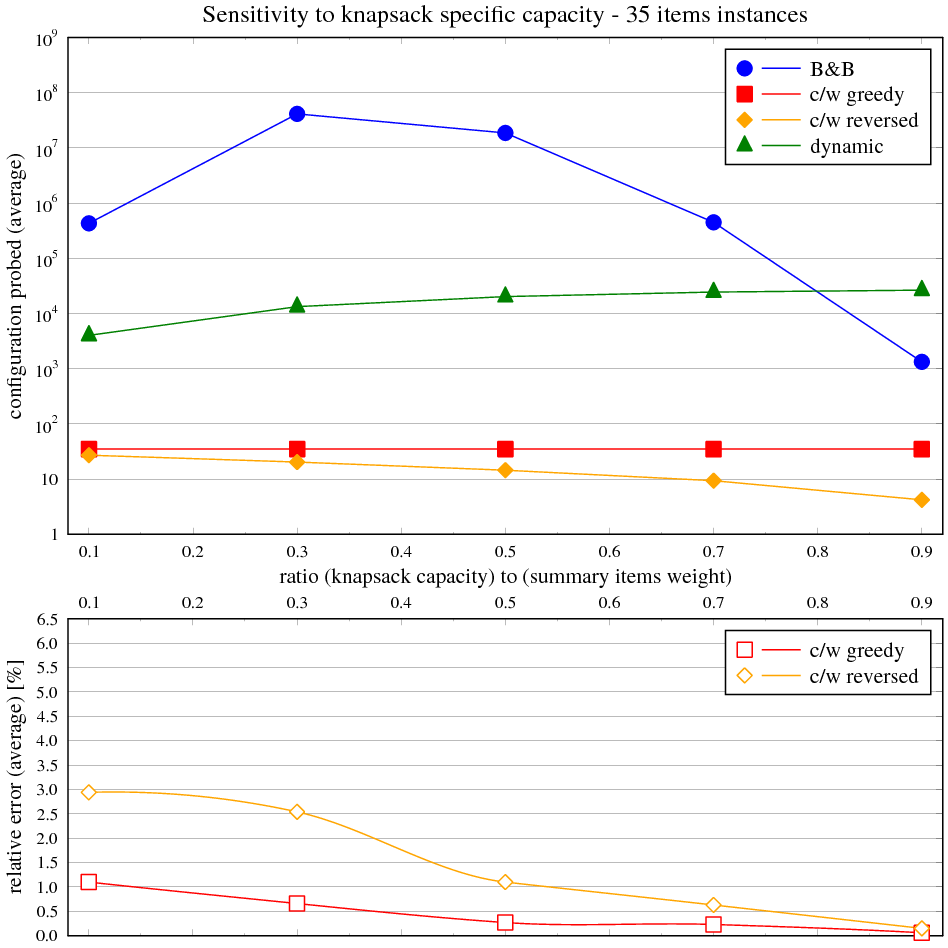
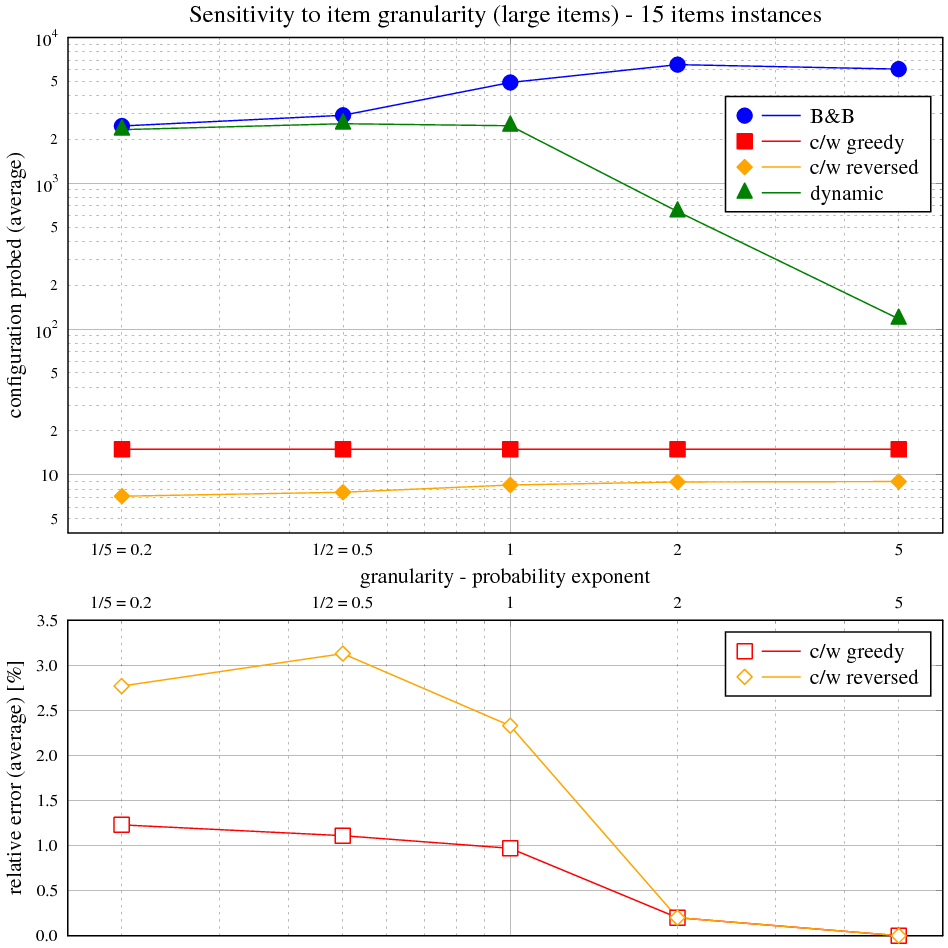
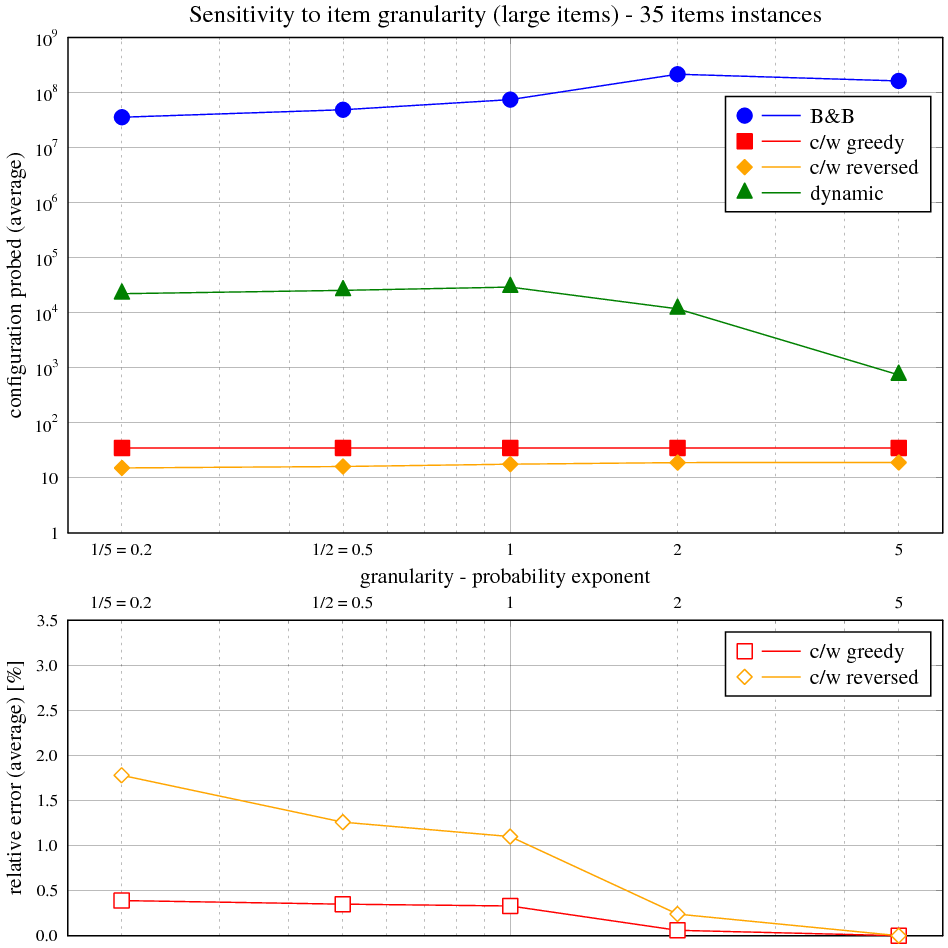
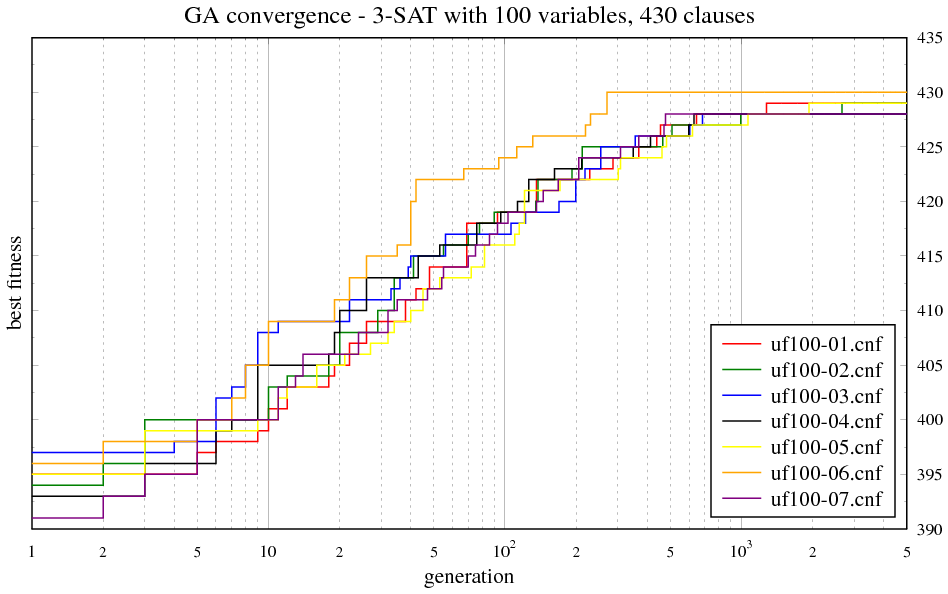
Zadání
- Naprogramujte řešení 0/1 problému batohu hrubou silou. Na zkušebních datech pozorujte závislost výpočetního času na n.
- Naprogramujte řešení 0/1 problému batohu heuristikou podle poměru cena/váha. Pozorujte
- závislost výpočetního času na n. Grafy jsou vítány (i pro exaktní metodu).
- průměrné zhoršení proti exaktní metodě
- maximální relativní chybu. Absolutní chyba nic neříká!
Platforma
Úloha byla řešena programem napsaným v jazyce C (ansi). Program "batoh" je parametrizován požadovaným algoritmem, počtem jeho iterací pro měření času krátkých zadání a na standardním vstupu očekává instance problému ve "školním" formátu. Na standardím výstupu se objevují řešení ve "školním" formátu. Aplikace je nezávislá na host OS.Řešení hrubou silou (bruteforce)
Algoritmus prochází všechny konfigurace batohu a pamatuje si tu, která nejlépe vyhovuje optimalizačnímu kritériu. Tok programu je řízen rekurzí, která v každém kroku rozhoduje o umístění jedné věci do batohu. Pokud by vložení této věci způsobilo přetížení batohu, použije se pouze cesta rozvíjející konfigurace, které tuto věc neobsahují. Tato optimalizace poněkud prořezává strom rekurzivního sestupu (ve verzi programu implementující prořezávání shora i zdola není tato optimalizace u metody hrubé síly použita).Časová složitost je O(2n), protože v každém kroku rekurze se program větví obecně do 2 cest, tak aby v pokryl všechny možné konfigurace. Paměťová složitost je O(n), protože pro každou věc udržujeme informaci o vložení/nevložení která je v případě rekurzivního přístupu realizována pozicí v programu a ukládána v aktivačních záznamech na HW zásobníku.
Řešení hladovým přístupem s heuristikou typu cena/váha (c/w greedy heuristic)
Algoritmus realizuje hladový výběr a proto nezaručuje optimální řešení. Dokonce nezaručuje žádnou max. relativní odchylku od optimálního řešení. Hodnotícím kritériem pro výběr je poměr ceny a váhy věci. Algoritmus nejprve provede řazení věcí instance podle tohoto poměru a poté je od prvku s největším poměrem přidává do batohu, pokud zůstane nepřetížen.Časová složitost je složitost řazení a procházení jednorozměrného pole, tozn. O(n*log(n) + n). Paměťová složitost je O(n), protože udržujeme informaci o mapování původních prvků do seřazenéného pole abychom byli schopni rekonstruovat vektor řešení s prvky v původním pořadí.
Naměřené výsledky
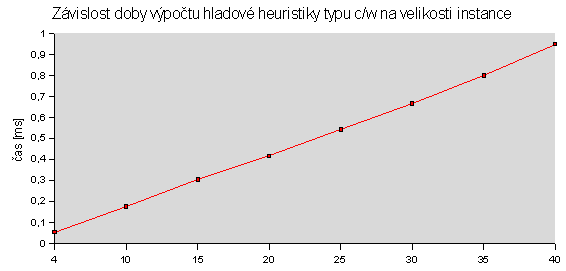
Čas byl měřen na CPU Athlon XP 1600+, OS Windows XP v prostředí cygwin programem time (user) parametrizovaným voláním programu batoh. V případě potřeby byl nastaven počet opakování požadovaného algoritmu uvnitř programu batoh na více než 1 (typicky 1000000, 10000, 100) tak, aby byl minimalizován režijní čas načtení úlohy vůči času běhu algoritmu pro vlastní řešení nebo pro velmi malé výpočetní doby. Vstupem byly školní instance problému.
|
|
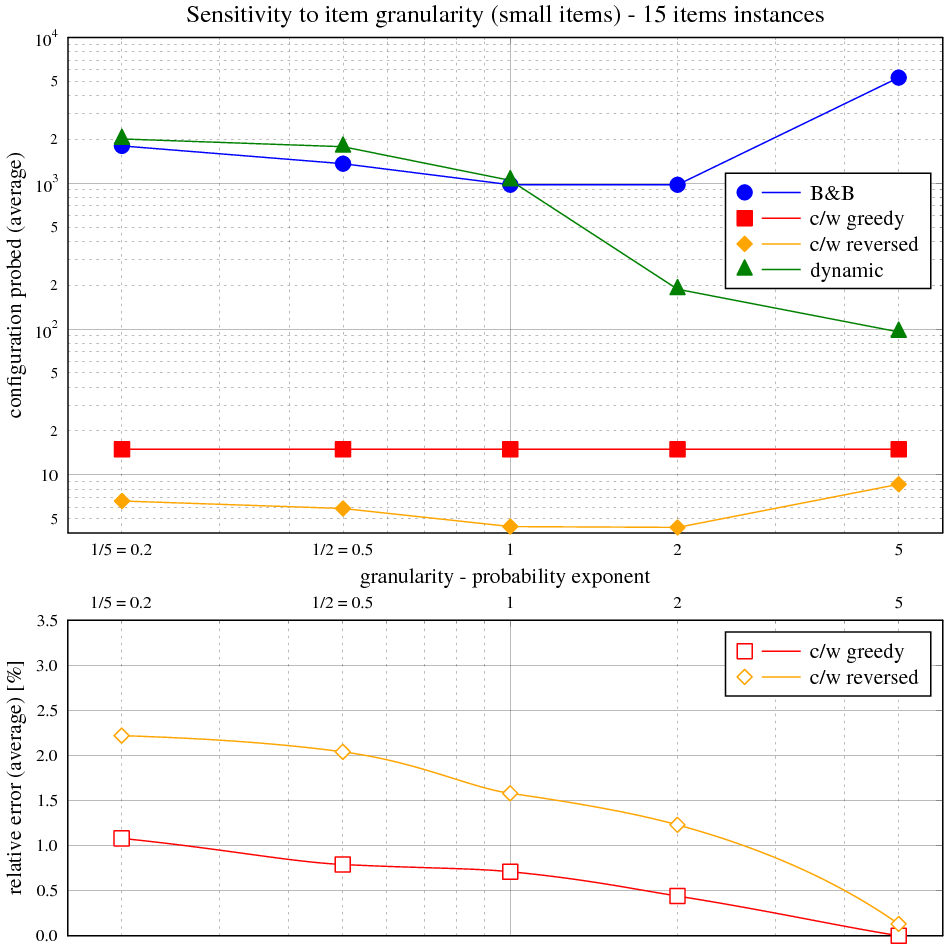
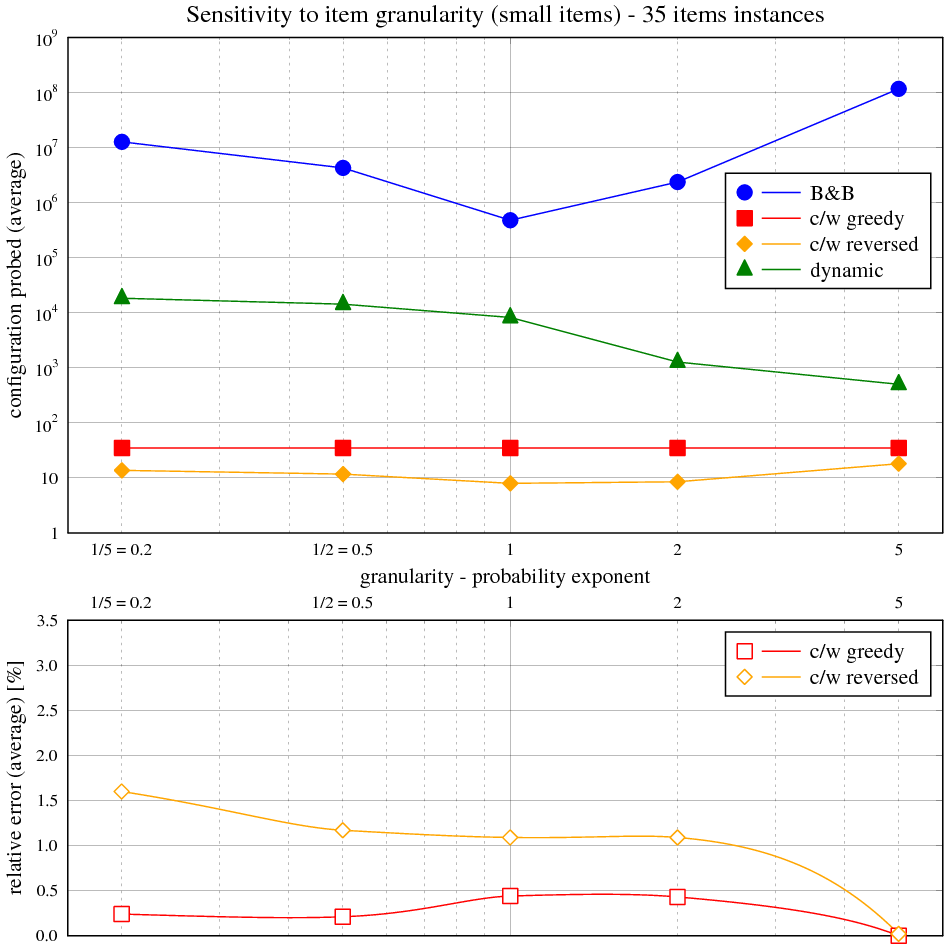
Vidíme, že časová složitost hrubé síly přesně odpovídá exponenciálnímu průběhu v celém rozsahu velikosti instancí. Složitost hladového výběru s heuristikou je asymptoticky lineárně-logaritmická, ale kvůli přidané lineární složce je tento trend viditelný jen nepatrně.
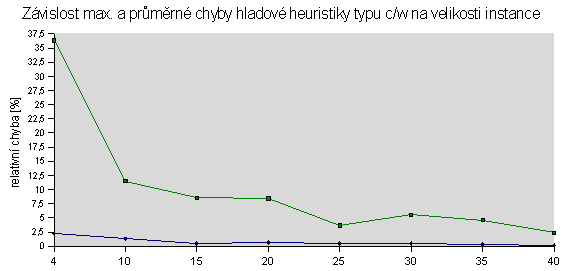
Následující tabulka ukazuje maximální a průměrnou relativní chybu řešení s hladovou heuristikou vůči optimálnímu řešení. Obě veličiny jsou vyjádřeny v závislosti na velikosti instance v balíku 50 testovacích. Relativní chyba je rozdíl mezi součtem cen věcí v batohu na výstupu měřeného algoritmu a největším možným, normalizovaným k němu (kladná chyba znamená méně hodnotný batoh, záporná není možná).
|
|
Závěr
Oba algoritmy pracují dle předpokladu. Hrubá síla nachází optimální řešení, avšak se značnou časovou složitostí, což potvrzují výsledky měření. Hladový přístup s jednoduchou heuristikou nezaručuje optimální řešení, což ukazuje tabulka s relativní chybou vůči němu. Tato nevýhoda je kompenzována podstatně nižší časovou složitostí algoritmu, která pro malé velikostio instancí vychází jen nepatrně superlineární.Odkazy
Zdrojový kód programu batoh zdeMakefile zde